Gutenberg Literary Clock as a service
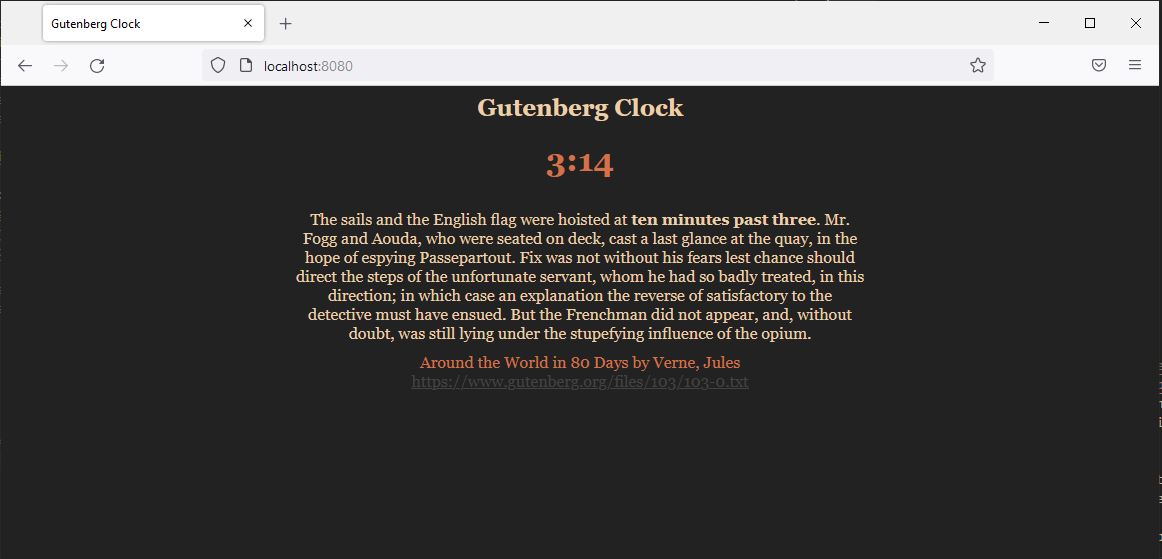
We use the previously created literary clock database to create a blazingly fast web service. You can get the full code here but remember that you also need the lit_clock.db file generated here
This article will be a short one. Converting gutenberg-clock to a webservice can be as easy as doing a SELECT on sql for each request, but to make things more interesting, we are going to make it faster.
We will be using actix-web as a web service framework as it is the fastest Rust web service framework currently benchmarked by techempower and it’s actually not hard to use.
We will have four endpoints, two of which will handle some sort of server side render of the clock and the other two will be used to serve json data (for your own display pleasures). We define the endpoints as functions that implement responders and we also have an AppState that will be populated with the sqlite database we created in the previous article.
#[actix_web::main]
async fn main() -> std::io::Result<()> {
HttpServer::new(|| {
App::new()
.app_data(web::Data::new(AppState::new("lit_clock.db")))
.service(html_clock)
.service(json_clock)
.service(custom_html_clock)
.service(custom_json_clock)
})
.bind(("0.0.0.0", 8080))?
.run()
.await
}
The more “advanced” code will be in the AppState creation part as the other parts are standard:
#[get("/")]
async fn html_clock(data: web::Data<AppState>) -> impl Responder {
let time = Local::now();
let show = data.get_html(time.hour12().1, time.minute());
HttpResponse::Ok().body(show)
}
#[get("{hour}/{minute}")]
async fn custom_html_clock(
data: web::Data<AppState>,
info: web::Path<(u32, u32)>,
) -> impl Responder {
let show = data.get_html(info.0, info.1);
HttpResponse::Ok().body(show)
}
#[get("/json")]
async fn json_clock(data: web::Data<AppState>) -> impl Responder {
let time_now = Local::now();
web::Json(data.get_entry(time_now.hour12().1, time_now.minute()))
}
#[get("/json/{hour}/{minute}")]
async fn custom_json_clock(
data: web::Data<AppState>,
info: web::Path<(u32, u32)>,
) -> impl Responder {
web::Json(data.get_entry(info.0, info.1))
}
So for the blazingly fast part we will hold all the info in memory, as the sqlite db itself is not that big (only around 8 mb). We also hold the data so we don’t pay for finds when we get a request. Because the data we are serving is read only and small we can get around the hdd access delay and only pay with some memory. Also we can have constant access time per request if we populate the data in a good structure.
// this data is the model we have in the SQLITE db, nothing new here
#[derive(Serialize, Clone)]
pub struct ClockEntry {
time: u32,
text: String,
author: String,
title: String,
link: String,
}
To check how we achieve constant time access for our problem without duplicating data we can look at the AppState structure
// this will mark a range of quotes
#[derive(Copy, Clone)]
pub struct Range {
min: i32,
max: i32,
}
pub struct AppState {
// all our database items sorted by time
all_entries: Vec<ClockEntry>,
// an array that holds the ranges from all_entries that are corresponding to the number of minutes we want to show
time_index: Vec<Range>,
}
So for each request we will have mainly two indirections. An indirection that will give us the range of indexes from which we can pick and one to actually get the info from all_entries. To populate this correctly we will need to get all database entries sorted by time and hold them in AppState. Find more details in the comments below.
impl AppState {
pub fn new(db_filename: &str) -> AppState {
// open the SQLITE connection
let fts_connection = Box::new(Connection::open(db_filename).unwrap());
// select all database entries sorted by time
let mut stm = fts_connection
.prepare("SELECT time, text, author, title, link FROM littime order by time;")
.unwrap();
// populate all_entries from the query
let data = stm
.query_map((), |row| {
Ok(ClockEntry {
time: row.get(0).unwrap(),
text: row.get(1).unwrap(),
author: row.get(2).unwrap(),
title: row.get(3).unwrap(),
link: row.get(4).unwrap(),
})
})
.unwrap()
.map(|entry| entry.unwrap())
.collect::<Vec<ClockEntry>>();
// we preallocate and resize the times array
let mut times: Vec<Range> = Vec::with_capacity(13 * 60);
times.resize(13 * 60, Range::default());
let mut prev_packed_index = 0 as usize;
// the main idea is to go through all data in order and populate missing time ranges with previous ones
for (idx, time) in data.iter().enumerate() {
// we first decode the hour and minute from our database representation
let hour = time.time / 100;
let minute = time.time % 100;
// we do a packed representation (no useless values) so we consume less memory
let packed_index = (hour * 60 + minute) as usize;
// when we get to a new time value we need to populate the missing ones
if packed_index != prev_packed_index || idx == 0 {
// populating the missing values with previous ones
let dif_index = packed_index - prev_packed_index;
if dif_index > 1 {
for i in 1..dif_index {
times[prev_packed_index + i] = times[prev_packed_index];
}
}
// adding the new range into our array
times[packed_index as usize] = Range {
min: idx as i32,
max: idx as i32,
};
} else {
// updating the range end until we change the packed_index
times[packed_index as usize].max = idx as i32;
}
// update the previous index
prev_packed_index = packed_index;
}
// return the computed AppState
AppState {
all_entries: data,
time_index: times,
}
}
}
Getting an entry in this data structure is straight forward:
// impl AppState
fn get_entry(&self, hour: u32, minute: u32) -> ClockEntry {
// input sanitization for hour
let h = match hour {
0 => 12,
1..=12 => hour,
13.. => hour % 12,
};
// input sanitization for minute
let m = match minute {
0..=59 => minute,
60.. => minute % 60,
};
// we want to check our performance
let now = Instant::now();
// build the index
let index = h * 60 + m;
// get the range
let range = self.time_index[index as usize];
// some debug output
println!("range {} - {}", range.min, range.max);
// if we only have one entry, avoid calling random for nothing
if range.min == range.max {
return self.all_entries[range.min as usize].clone();
}
// get a random valid index
let index_show = rand::thread_rng().gen_range(range.min..range.max) as usize;
// print how long it took
println!("entry elapsed: {:.2?}", now.elapsed());
// return the entry
return self.all_entries[index_show].clone();
}
// this will get the html template and replace the values with our entry values
fn get_html(&self, hour: u32, minute: u32) -> String {
let now = Instant::now();
let html_raw = include_str!("clock.html");
let entry = self.get_entry(hour, minute);
let mut html = html_raw.replace("{{author}}", clean_string(&entry.author).as_str());
html = html.replace("{{title}}", clean_string(&entry.title).as_str());
html = html.replace("{{link}}", &entry.link);
html = html.replace("{{paragraph}}", &clean_string(&entry.text).as_str());
html = html.replace("{{time}}", format!("{}:{}", hour, minute).as_str());
println!("html elapsed: {:.2?}", now.elapsed());
return html;
}
On my old i7-6700K cpu with DDR4 memory I get sub nano second times on average. Sometimes when dealing with a lot of text the clean_string function may take more time. This could be fixed by cleaning strings when populating the data structure. I did not do that because I wanted to serve the original string on the json endpoint, but feal free to try.
- entry elapsed: 165.90µs
- html elapsed: 730.10µs
- range 1961 - 1965
- entry elapsed: 348.40µs
- html elapsed: 1.19ms
- range 1961 - 1965
- entry elapsed: 283.60µs
- html elapsed: 728.20µs
- range 1961 - 1965
- entry elapsed: 311.80µs
- html elapsed: 849.50µs
I believe that optimizing power consumption by using resources carefully will help everybody long term. This is why I am very happy to see Rust gaining popularity on web-servers.